Breadcrumbs to the Goal: Goal-Conditioned Exploration from Human-in-the-Loop Feedback
Abstract
Exploration and reward specification are fundamental and intertwined challenges for reinforcement learning. Solving sequential decision making tasks with a non-trivial element of exploration requires either specifying carefully designed reward functions or relying on indiscriminate, novelty seeking exploration bonuses. Human supervisors can provide effective guidance in the loop to direct the exploration process, but prior methods to leverage this guidance require constant synchronous high-quality human feedback, which is expensive and impractical to obtain. In this work, we propose a technique - Human-Guided Exploration (HuGE), that is able to leverage low-quality feedback from non-expert users, which is infrequent, asynchronous and noisy, to guide exploration for reinforcement learning, without requiring careful reward specification. The key idea is to separate the challenges of directed exploration and policy learning - human feedback is used to direct exploration, while self-supervised policy learning is used to independently learn unbiased behaviors from the collected data. We show that this procedure can leverage noisy, asynchronous human feedback to learn tasks with no hand-crafted reward design or exploration bonuses. We show that \Method is able to learn a variety of challenging multi-stage robotic navigation and manipulation tasks in simulation using crowdsourced feedback from non-expert users. Moreover, this paradigm can be scaled to learning directly on real-world robots.
Method
Real World Experiments

Accomplished goals at the end of 5 different evaluation episodes along training in the real world.
Simulation Experiments

Six simulation benchmarks where we test HuGE and compare against baselines. Bandu, Block Stacking, Kitchen, and Pusher, are long-horizon manipulation tasks; Four rooms and Maze are 2D navigation tasks
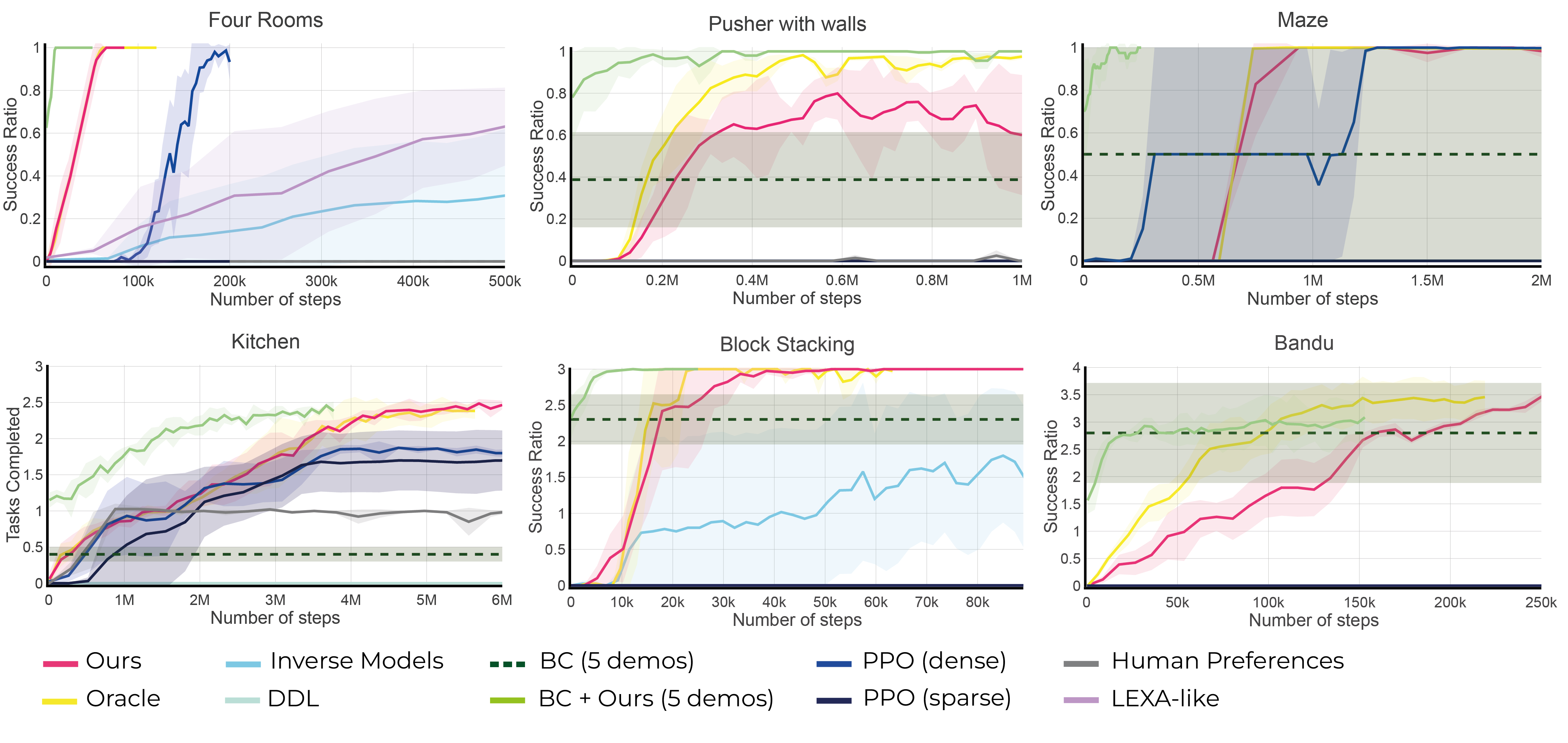
Success curves of HuGE on the proposed benchmarks compared to the baselines. HuGE outperforms the rest of the baselines, some of which cannot solve the environment, while converging to the oracle accuracy. For those curves that are not visible, it means they never succeeded and hence are all at 0 (see D.9 in the paper for distance curves). Note the lexa-like benchmark is only computed in the four rooms benchmark. The curves are the average of 4 runs, and the shaded region corresponds to the standard deviation.
Crowdsourced Experiments
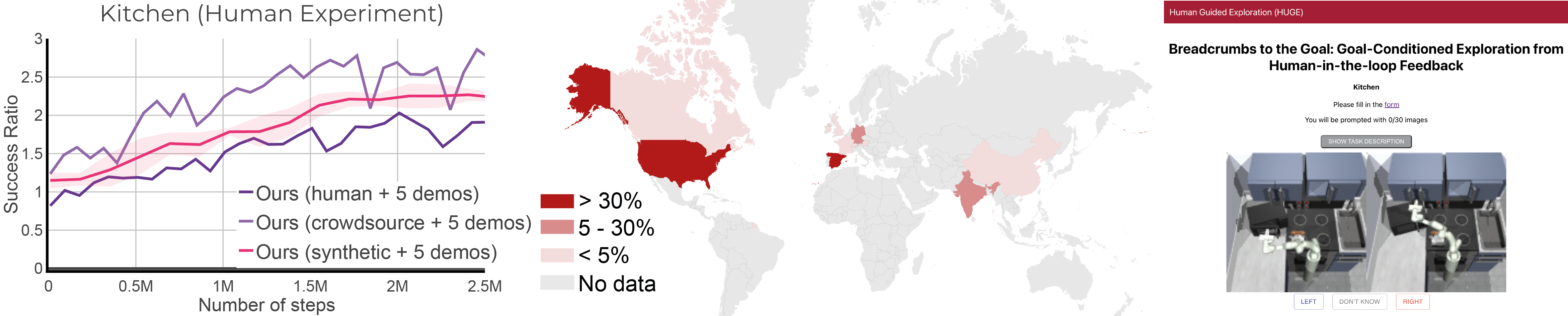
left: Crowdsourcing experiment learning curves for the kitchen, middle: human annotators spanned 3 continents and 13 countries, right: screenshot of the interface for data collection.
Robustness to Learning from Noisy Human Feedback
Analysis
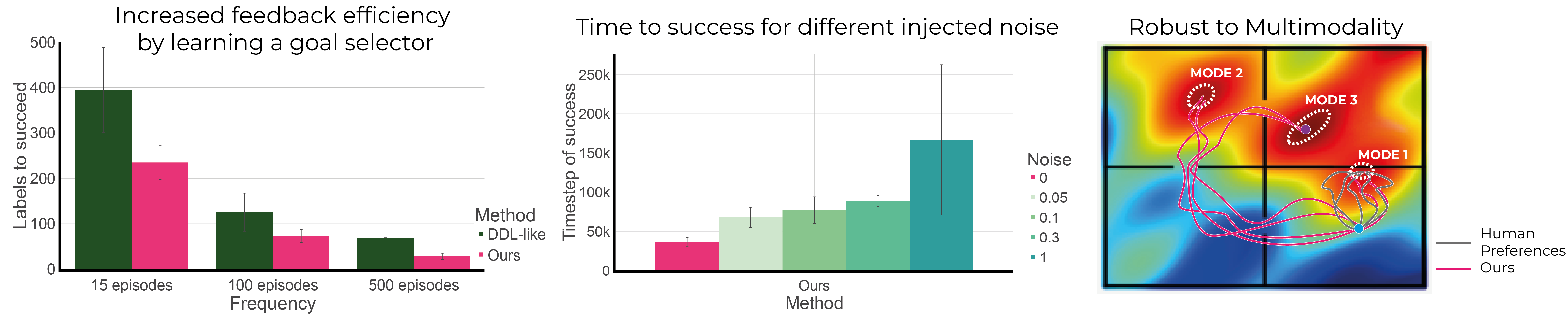
left: Learning a goal selector (Ours) needs on average 50% fewer labels than not (DDL) middle: As the noise in the feedback increases, so will the number of timesteps to succeed, however HuGE still finds a solution. right: HuGE is robust to noisy goal selectors since trajectories going to each mode will be sampled while if we ran RL the policy would become biased and fail. See Appendix E in the paper for more details.